
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 코닥 미니샷2
- 약과팅 경험!
- clone vs pull
- 장인한과
- 성공했으면 꿀팁! 이런거라도 적는데 그게 아니니 뭐 적을게 없네요
- 회사 네트워크
- git 충돌
- android xml 오류
- OSI 모델
- 전기신호
- git #
- 모두의 네트워크
- git
- 안드로이드 xml 화면 오류
- network
- 네트워크 기초
- FCS
- 역캡슐화
- Git 기초
- Android
- xml화면 검은색
- 장인약과
- kakaomap
- xml 화면
- 카카오맵 api
- android xml 화면 검은색
- 가정 네트워크
- KakaoMap API
- 약과팅
- TCP/IP 모델
- Today
- Total
괴발개발
인공지능3 ( 알고리즘 종류, feature, label, decision tree, random forest, 붓꽃, seaborn, label encoder, onehot encoder,pandas.get_dummies()) 본문
인공지능3 ( 알고리즘 종류, feature, label, decision tree, random forest, 붓꽃, seaborn, label encoder, onehot encoder,pandas.get_dummies())
yousim 2021. 10. 22. 13:23머신러닝 알고리즘 종류
Expert Systems : 전문가 시스템
Classfication
-개체가 속한 카테고리 식별
- 클래스화/ 분류하는 엔진
Regression
-개체와 관련된 연속 값 특성 예측
- 회귀 / ex) 주가의 오르내림을 예측 가능. 패턴을 공부
--> 이 두개가 대표적인 지도학습 (sporvised learing) 의 사례--> 조건과 답이 있어야함. (ex) 이런건 사과야~이런건 배야~ 이럼서 답을 알려주고 특징들을 공부.
-->라벨링 : 분류를 하는것.
*** feature(특성) ,label(결론),
Clustering
-유사한 객체를 세트로 자동 그룹화
Dimensionality reduction
-고려할 랜덤 변수의 수 감소
-몇백개의 데이터를 넣어서 유추해내는것. 계속 반복해야함.
-->이 두개가 비지도학습 , --> 답을 안 알려주고 컴퓨터에 데이터를 넣으면 이것들의 패턴을 분석하여 그룹핑을 하고, 사용자가 label을 유추. 이후 classification.
Classification~dimen
모두 Estimators (예측)
Model selection
-파라메터과 모델들을 비교, 검증 및 선택
Preprocessing
-feature 추출과 표준화
기계학습을 하는 순서 :
데이터 수집 ( feature 데이터와 label데이터)
학습 알고리즘 결정
데이터 나누기 – 학습데이터 : 테스트 데이터 = 8:2
학습하기
예측하기
평가하기
feature데이터 : 여러요소를 가지는 벡터형태의 데이터
label 데이터 : feature 들의 조합이 가지는 실세계 결과값


decision tree : 의사결정트리. 특정 질문에 따라 데이터를 구분하는 지도 학습 모델.
random forest : 여러 개의 의사결정트리를 만들고, 투표를 시켜 다수결로 결과를 결정하는 방법. 오버피팅(이후에 들어오는 데이터에 대해 성능저하되는 현상) 될 가능성 낮춤
--> 이 두 개 다 scikit-learn에서 제공된다.
LabelEncoder : 문자로 되어있는 것을 숫자로 표현하는 encoder, 각 고유항목에 숫자코드를 부여하여 column에 기록
LabelEncoder의 문제점 : TV는 5, Computer는 0으로 코딩이 되었다. 여기서 숫자의 크기는 의미가 없으나, ML 로직이 숫자 크기에 따른 의미가 있는것으로
착각하게 된다. 이를 해결하고자 각각의 이름을 vector 요소로 바꾸는 OneHotEncoder를 쓰게 된다.
상품분류 필드에 코드를 넣는게 아니라, 각각의 이름에해당하는 필드를 만들고, 해당 이름인 경우에 1, 아닌 경우에 0을 넣어서, 입력 벡터에 동등한 수준을 가지게 한다.
OneHotEncoder : 각 고유 항목별로 별도의 column을 만들고 해당 여부를 0과 1로 구분. >> label encoding을 거쳐야함.
pandas.get_dummies() : ohe 대신에 get_dummies()사용을 추천.
>>oeh는 실행을 위해 여러 절차가 필요. 이는 매우 쉽게 oeh가능.
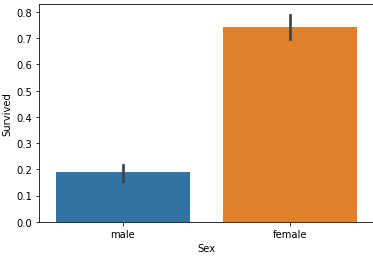
SeaBorn : python에서 사용가능한 가장 유용한 시각화 라이브러리
'Study > 인공지능' 카테고리의 다른 글
| [AI-Expert-Roadmap] AI 전문가가 되기 위한 로드맵 1일 (0) | 2022.02.17 |
|---|---|
| 인공지능5 (Accuracy)(예측평가 - 정확도, 정밀도, 재현율, F-1 Score) (0) | 2021.10.22 |
| 인공지능4(titanic) ( data preprocessing, fit(), predict()) (0) | 2021.10.22 |
| 인공지능2 (NumPy,ndim,shape,arange,zeros,ones,reshape, 슬라이싱, fancy indexing, np.sort, ndarray.sort, argsort) (0) | 2021.10.21 |
| 인공지능 (AI, Colab, Python, list, tuple, set, dictionary) (0) | 2021.10.21 |
